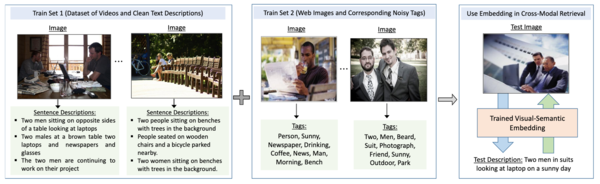
The problem setting of our paper. Our goal is to utilize web images associated with noisy tags to learn a robustvisual-semantic embedding from a dataset of clean images with ground truth sentences. We test the learned latent space byprojecting images and